大数据流失用户预警和处理
本文记录一下用大数据对流失用户的预警和处理的想法流程。
模块名
流失用户预警
需求
根据用户行为,预判可能会流失的用户,并根据用户流失概率给予建议的回馈值。
开发和思考流程
首先,定义流失用户,然后进行用户分群找到流失用户所在群后回归,找到尚未流失的高风险用户,根据风险值和用户能提供的收益值,计算出保障增加收益的前提下建议进行的回馈值。
具体步骤
定义流失用户
什么叫流失?
流失用户不能定义为“一个用户永远不上线”。因为有些用户数个月不登录,依然可能再度登录。
所以我们需要定义一个天数K,当用户K天没有登入时,我们就需要算该用户为流失。
通常来说,当用户回返率低于5%时,这个天数就可以算作流失天数K。
那么什么是回返率?
假设T0这天有X个用户登录游戏,到T0+T天之后,这X用户中只有Y个用户在T天之间登录过,那么Y/X就叫回返率,我们设为λ.
λ = Y / X
我们的目的是求λ≈5%时的T。
我们对2016,2017期间数据进行了单月,半年,一年,20个月的数据筛选,发现T是呈现收敛的,部分数据如下图(注:根据图表特性,我们综合使用了中位数和平均数):

所以,我们认为会收敛于T = 35,即流失天为35,也就意味着:在这款游戏中,若一个玩家超过35天未曾登录游戏,就属于流失用户。
确定预警日
我们要做的是流失用户预警,必然要在用户真正流失之前就预测出他可能会流失。
所以预警日期,不可能大于35天……因为大于35天他就已经流失了。
所以预警日 N < 35
但是预警日期也不能太短,若过短,则会出现大量的冗余错误预警。根据上图中的时间段分析,这个值建议大于9,可去除最大量的冗余错误预警。
那么预警日为 9 < N < 35
因为我们的大部分游戏每周会有一些额外活动,对用户留存等行为影响很大,所以建议预警日以周为单位比较可靠。
那么预警日为 14, 21, 28
然后再次对14天,21天,28天未上线用户进行绘图,和35日流失用户绘图进行对比,发现21天的图形数据已经逼近35日流失图,且日期最短(越早预测越有利)
最终选定预警日为21天。
确定模型特征
OK,我们已经确定对用户前21天的数据进行统计,以确定高风险流失用户了。那么,我们该选取哪些数据特征来进行分析呢?
首先,我们主观根据业务做了一些特征选取,例如:游戏时长,账户余额等等
然后,我们根据已流失用户在流失之前 和 普通用户 在数据上的差异,选取了部分特征。例如:账户代币数量,活动进行量等
然后,无论哪个方法得到的特征,我们都进行统计检定进行客观测试,例如(相关系数,卡方检定,信息增益等方式)
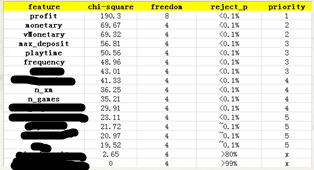
预测模型选取
OK,我们现既确定了预警时间,也确定了特征。那么我们如何建模,选取什么模型呢?
根据业务分析,我们发现当前的数据有一个特征:
我们用户流失率很低。以月为单位,流失率只有1%,即每月登录的用户,只有不足1%的用户在35天内不会登录。
这种特征的数据,若不做特殊的处理,很容易训练出错误的假结论。(即:预测结果为所有用户都不流失,此时的正确率是99%,因为99%的用户在月内不会流失,而这样的结果是毫无意义的,然而,如果仅以正确率为预测标准,那么99%的正确率已经很高,可能已经是最优预测)
所以,我们不能仅以预测的“准确度 accuracy”为判定标准。我们要充分考虑“覆盖率 recall”和“精确率 precision”。
覆盖率 recall:是指真正最终流失的用户中,我们实际预测到了多少。例如:1000个用户,最终真正流失了100个用户(900个未流失),我们提前预测到了其中的60个,那么覆盖率就是60%。
精确率 precision:是指错误预测的未流失用户有多少。例如:1000个用户,最终真正流失了100个用户(900个未流失),我们提前预测到了其中的60个,但是还错误预测了20个(这20个用户实际上最终未流失),那么精确率就是(60/(60+20))≈75%
一般来说,针对这种非均衡数据集,高覆盖率和高精确率,我们只能二选一。我们来考虑后果:
高覆盖率,低精确率:训练后会产生一定“误预警”,游戏项目组会花费额外的资金来尝试留住一些实际并不会流失的用户。但流失用户会抓的很准,也会大部分会被覆盖进来。
高精确率,低覆盖率:产生的数据结果集会比较小,游戏项目组不会有太多无谓的开销,但同时,对流失用户的预测会不太有效。
在和项目组沟通后,我们愿意以给定一些额外开销来支持高覆盖率。
所以最终结果是:保证高覆盖率的前期下保证高准确度,不对精确率做太高要求。
进一步分析高覆盖度
Step1: 假设我们一个用户进入游戏,平均每日能创造X的营业额 而我们期望这个用户能多在游戏中呆P%天,实际天数则为 35 * P% 则,最终这个用户会为游戏增加收益为 X * (35 * P%) 而维护该用户在未来35天内上线花费的成本为Y 那么该用户未来35天的净利润为 T = X * (35 * P%) - Y
Step2: 假设总流失人数为u 覆盖率为q 精确率为s 那么被预测到的真实流失用户人数为 uq 那么这些流失用户被留下的话,会产生利润为 uq * T = uq * (X * (35 * P%) - Y) 那么被误预警的用户人数为 uq((1-s)/ s) 我们为这些误预警的用户额外开销为 uq((1-s)/ s) * y 而这些用户原本就不会流失的,所以可以认为额外收益为0 所以这些被误预警的用户未来35天的净利润为 T = 0 - uq((1-s)/ s) * y
Step3: 所以这个方程最终总收益为 uq * (X * (35 * P%) - Y) - (uq((1-s)/ s) * y) 只要这个值大于0,则表示我们有额外的收益了。 解方程最终得到: 100 * y < 35 * p * s * x 即可获得正收益。
确定回馈值
我们继续看上面的step3公式:
其中x - 每个用户平均日创造价值是固定的。 其中s - 一旦算法确定,s值是被确定的。 所以建议回馈值,仅仅和 p 有关。即期望流失用户在游戏中额外留存的日期。
此时,我们结合上一篇文章的用户分群,对不同分组的用户做了不同的回馈值分析,就得到了每个用户可能的流失情况以及建议的回馈值。
具体这些回馈值的回馈方式,就是游戏产品的事情了。
细节
PCA验证特征
我们获取了特征之后,通过PCA降维之后,发现流失用户和普通用户分群良好,说明特征量选取很好,可预测结果会比较理想。
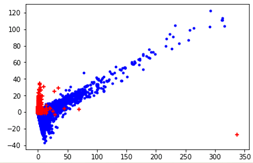
其中红色点为35天后会流失用户;蓝色点为普通用户。可以看到两者虽然有重合现象,但基本上可以分辨两种行为方式不同的群体。
模型选取方式
我们使用了三种模型,分别进行测试后进行了如下比较。
逻辑回归
在正则化参数C时,做交叉选取确定了比较好的准确度accuracy和覆盖度recall.如下图:
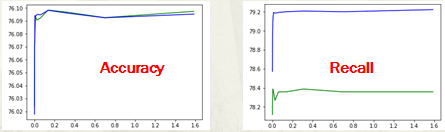
其中绿色曲线为测试数据,蓝色曲线为训练数据。
最终选择了C=5.14175183e-3,此时覆盖率为 78.34,准确率为76.09
而腾讯信鸽系统对手游流失预测也是使用逻辑回归,其覆盖率为 79.84, 准确率为85.646 (参见 腾讯信鸽系统 )
SVM 支持向量机
我们使用了 径向基函数 RBF( Gaussian Kernel),其中做交叉选取的有两个参数:核参数α和C
我们先固定C=1,交叉选取求α,最终得到最好覆盖率和准确率时α=0.00129155 然后我们固定α=0.00129155,交叉选取求C得到最好覆盖率和准确率时C=0.0000001
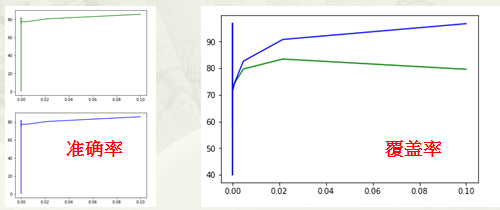
SVM计算消耗时间过长,为三天,不能适应需求,所以放弃。
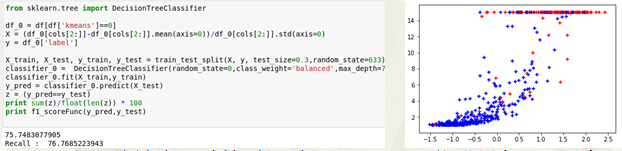
决策树 DecisionTree
结果和逻辑回归差不多,但对于非平衡数据不能很好的分布式处理,所以放弃。
幸存分析 CoxPH
缺点是覆盖率只有67%,不如其他模型,所以放弃。
最终我们选择了LR逻辑回归。
一句话回顾流程
1:获取【35天之前的部分数据A】作为训练资料 2:通过训练资料和流失模型,重新计算准确度和覆盖度 3:模型监控进程始终监视准确度和覆盖度,若达到标准,则根据【昨天上线用户最近21天的行为】进行流失用户预测,同时将【35天之前的全部数据】放置入参考库,结束。 4:若准确度和覆盖度未达到标准,则通过参考库数据重新训练模型,更新模型后,重新通过【35天之前的部分数据A】计算准确度和覆盖度,重复步骤3和4,直到流失模型的准确度和覆盖度达标。
其他
扩展性
根据用户消费能力级别,在准确度和精确度之间进一步加入权值。
根据新流失用户数据,反向强化训练集。

